когда документации нет, а данные есть
Гайд для аналитиков: три взгляда на одну проблему — методология, реальный опыт, грабли и победы
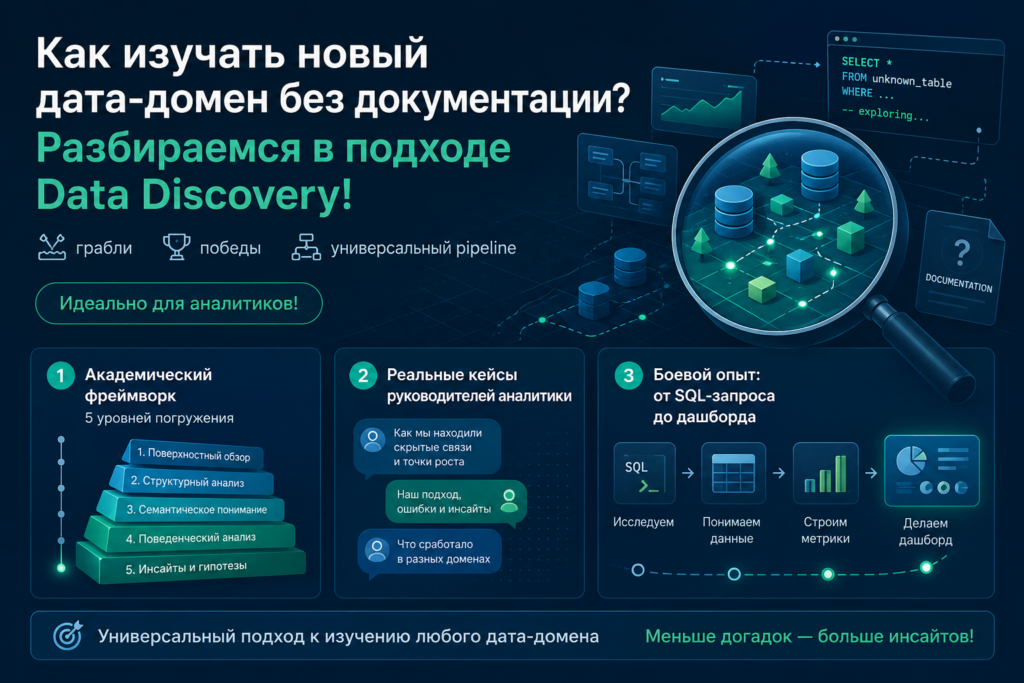
Введение
История начинается стандартно: в работе аналитического подразделения появляется новый, большой и специфичный блок данных. В моем случае — телефония: сотни миллионов записей, сотни признаков. Никакой документации, схемы данных или подсказок — «куда смотреть», «что смотреть», «зачем смотреть».
Как к этому подойти? Я собрал три точки зрения:
- «Академический Data Discovery‑фреймворк» — что говорят наука и практика Data Engineering.
- «Реальные кейсы руководителей аналитики» — как коллеги разгребали такое же.
- «Боевой опыт» — путь от SQL‑запроса до дашборда, с шишками и озарениями.
Часть 1. Data Discovery: научный подход к неизвестности
Что такое Data Discovery?
Data Discovery — это не просто «посмотреть данные». Это процесс идентификации, каталогизации и первичного понимания данных. IBM определяет его как «сбор, оценку и исследование данных из множества, часто разрозненных источников, чтобы никакая ценная информация не ускользнула» (IBM, 2026).
Ключевое отличие от обычного EDA (Exploratory Data Analysis):
- EDA ищет инсайты и паттерны;
- Data Discovery — сначала про мета‑понимание: структуру, качество, связи. Это разведка перед боем.
Фреймворк: 5 уровней погружения
По методологии, собранной из практик, рекомендаций и опыта data‑команд, процесс изучения нового дата‑домена выглядит так:
Уровень 0. Source Intelligence (Sage, 2026)
Прежде чем открыть SQL — нужно понять, откуда данные берутся:
- Какой источник? Прямая БД, API, выгрузка?
- Когда последний раз обновлялись?
- Кто за них отвечает?
- Фильтровались / агрегировались / чистились?
Уровень 1. Data Profiling (Airbyte, ObservableHQ)
Систематический технический анализ:
- Сколько таблиц? Сколько колонок?
- Типы данных (
int,varchar,timestamp) — соответствуют ли заявленному? - Nullability — где
NULLи почему? - Уникальность ключей — есть ли первичные/внешние ключи?
- Граничные значения (
min/max) — аномалии на краях.
Уровень 2. Structural Discovery (Amazon Well‑Architected Framework)
- Построение связей: что с чем может быть связано.
- Проверка consistency типов в потенциальных FK‑связях.
- Поиск естественных ключей (комбинаций, которые образуют уникальность).
Уровень 3. Domain Understanding (ObservableHQ, EDA framework)
- Dimensions vs Measures (Baraa Khatib Salkini).
- Временные ряды: глубина истории, дискретность, сезонность.
- Распределение данных: кардинальность категорий, разрежённость.
Уровень 4. Business Mapping
- Перевод колонок и связей в бизнес‑термины.
- Data Dictionary (пусть и reverse‑engineered).
- Валидация с бизнесом.
Data Profiling vs EDA: что есть что
Важный момент, который часто путают:
| Data Profiling | EDA |
|---|---|
| Проверка структуры | Поиск паттернов |
| Количество NULL, дубликатов | Распределение, тренды |
| Типы данных, constraints | Корреляции, аномалии |
| Ответ: «данные выглядят здоровыми / больными» | Ответ: «в данных есть вот это и вот это» |
Data Profiling — обязательный шаг перед EDA, если вы не уверены в источнике.
Часть 2. Реальные кейсы: как аналитики подходят к незнакомым данным
Кейс: от знакомого Head of Data
Проблема: пришёл на новое место — legacy‑система (пусть будет какого‑нибудь скоринга), документация на уровне «раньше Вася всё знал» (на Habr хватает аналогичных примеров).
Что сделали:
- Сначала — автоматический Data Profiler (
YData Profiling/pandas‑profiling) на сэмпле 100 К записей, очень долго считает. Важно: брать разные выборки за разные периоды. Мы, например, столкнулись с утерянными данными за 2 месяца, а первоначальный отчёт не показал этого. - Параллельно — reverse engineering через SQL:
sql
SELECT column_name, data_type FROM all_tab_columns
- Построили «карту догадок» — гипотезу схемы.
- Валидировали с business owner: показали, данные или 10 примеров строк и спросили «что это?».
- Через 2 недели: Data Catalog в
dbt docsс комментариями.
Грабли:
- Сначала потратили месяц на «восстановление документации как было» — оказалось, что исходников всё равно нет, и это dead end.
- Перешли на «документируем только то, что используем в дашбордах».
- Параллельно дали бизнесу early дашборды («сырые» raw data метрики), чтобы бизнес сам начал указывать на странности.
Ещё кейс: телефония — синергия двух подходов
- Документация есть, но недостоверна → типичный Level 0 / Level 1.
- Схемы данных нет → Level 2 (Structural Discovery).
- SQL → просмотр данных, взаимосвязи непонятны → это и есть manual Data Profiling.
- EDA из DS → смотрим, что меняется → «если нет информации, куда смотреть, смотрим на то, что меняется» — гениальное эвристическое правило. Это Level 3 + Level 4.
- Дашборды‑прототипы → итеративный discovery через бизнес‑валидацию.
Ключевой момент: «лучше сделать быстро сырой дашборд, чем потратить месяц на идеальную модель, которая никому не нужна».
Часть 3. Боевой гайд: пошаговая инструкция для твоего кейса
Шаг 1. SQL‑рекогносцировка (Week 1)
Не лезь в документацию. Возможно, уже понятно, что её нет. Иди в данные.
sql
-- Разведка: профилирование всех таблиц
SELECT
table_name,
column_name,
data_type,
is_nullable
FROM information_schema.columns
WHERE table_schema = 'telephony'
ORDER BY table_name, ordinal_position;
sql
-- Кардинальность измерений
SELECT column_name, COUNT(DISTINCT value) as cardinality
FROM raw_telephony
GROUP BY column_name;
sql
-- Временной диапазон
SELECT MIN(call_start), MAX(call_start),
DATEDIFF('day', MIN(call_start), MAX(call_start)) as days_span
FROM calls;
Шаг 2. Data Profiling: минимальный набор
Obligatory чек‑лист:
- [ ] Null‑ratio по каждой колонке.
- [ ] Unique‑ratio (какой % уникальных значений).
- [ ] Min/Max/Mean для числовых.
- [ ] Most frequent values для строковых.
- [ ] Аномалии распределения (где 99 % в одной категории).
Инструменты:
- DBeaver (отлично, если данные большие — работает быстрее pandas на одной машине).
- Pandas Profiling для sample‑датасета (мне не помогло, а даже отправило не по тому пути).
great_expectations— если хочешь сразу заложить data quality expectations.
Шаг 3. Reverse Engineering схемы
Когда документации нет — строй гипотезы:
- Колонки, где FK‑синтаксис (
call_id,session_id,client_ext_id) — вероятные связи. - Поле
user_idв таблицеcall_detail→user_idв таблицеclients. - Проверь: есть ли колонка с совпадающими значениями в обеих таблицах.
Совет: сделай колонку «гипотеза связи» в своей заметке. Не доказывай — просто предположи. При проверке с бизнесом половина гипотез отпадёт, но структура появится.
Шаг 4. EDA: что меняется?
Подход «смотрим на то, что меняется» — это, по сути, change‑point detection (академически), или — «там, где непонятно — там интересно».
Что смотреть:
- Volume per day / hour → есть ли паттерн?
- Duration distribution → аномальные длительности.
- Missing data by time → пропуски в данных.
- Dropout: начатые vs завершённые звонки.
Шаг 5. Selective Analysis → Dashboard
- Стоит выбрать 3–5 вопросов от бизнеса (реальных или гипотетических).
- Построить максимально простой прототип дашборда (да, даже в Excel).
- Показать бизнесу.
- Собрать feedback.
- Итерировать.
“Да, это дольше…” Это единственный рабочий подход. Строить идеальный дашборд без понимания данных — гарантированный путь в никуда: нет гарантии достоверности данных, нет понимания… А с прототипом – проще говорить с бизнесом о данных.
Шаг 6. Операционализация
Когда понял данные и бизнес подтвердил метрики:
- Data Catalog (хотя бы внутренний:
dbt docsили Google Sheet с описанием колонок). - Data Quality мониторинг (когда данные «ломаются» — ты должен знать).
- Переход от manual dashboards к автоматическим.
Часть 4. Грабли: что точно пойдёт не так
1. Поверить документации
Я уже наступил на это.) Я и дальше буду проверять всё сам, что бы выявить такие ошибки как можно раньше.
2. Потратить месяц на «идеальную модель данных»
Это главная ловушка для аналитика. Бизнесу плевать на 3NF. Ему нужен ответ на вопрос «а что с конверсией?» — и да, на сырых данных, с погрешностью в 5 %.
3. Игнорировать бизнес до конца
Ошибка: «сначала разберусь сам, потом покажу». Нет. Нужно вовлекать бизнес с первого дашборда. Пусть видят сырые цифры. Спрашивай: «это нормально?».
4. Не заложить Data Quality
Телефония — грязный источник. Битые файлы, потерянные пакеты, дубликаты от ретраев. Если сразу не мониторить DQ — через месяц будешь гадать, почему метрика упала: данные сломались или бизнес просел.
5. Синдром самозванца
«Я не знаю телефонию. Я не эксперт по VoIP». Нормально. Ты — аналитик. Твой навык — разобраться в чём угодно через данные. У тебя уже есть SQL, EDA, Python, BI. Телефония — это просто ещё один набор таблиц.
Часть 5. Победы: что ты получишь
Когда пройдёшь этот путь:
- Ты будешь человеком, кто реально понимает эти данные. Документация — враньё, как правило, если разработчики ушли – то наверняка, твой reverse‑engineered dictionary — единственный источник правды.
- Дашборды начнут приносить бизнесу реальную пользу. Не «красивые графики», а ответы на вопросы: сколько звонков, какие конверсии, где потери.
- Ты построишь процесс. В следующий раз, когда появится новый источник — у тебя будет воспроизводимый pipeline: Profiling → Structuring → EDA → Prototype → Validation → Production.
- У тебя будет язык для разговора с бизнесом. Не «вот таблица call_center_fact_v2», а «вот сколько клиентов мы потеряли на IVR‑этапе».
Заключение
Эта история – не про телефонию, хотя она с неё началась.
Она про универсальный подход к неизвестным данным. Данных будет становиться только больше, источников — только разнообразнее, документации — только меньше.
Такой метод Data Discovery, применённый на практике, он не академический, он рабочий. Ну для меня точно. И когда ко мне придёт стажёр с вопросом «а как мне разобраться с новыми данными?» — я дам ему эту инструкцию.
Источники и ссылки
IBM. «What is data discovery?» — https://docs.aws.amazon.com/wellarchitected/latest/analytics-lens/data-discovery.html
Amazon AWS. Analytics Lens — Data Discovery — https://observablehq.com/blog/data-exploration-checklist
ObservableHQ. «How to explore data: A checklist for navigating datasets» — https://observablehq.com/blog/data-exploration-checklist
Sage Research Methods. «Initial Steps and Tests When Working With a New Dataset» — https://methods.sagepub.com/how-to-guide/initial-steps-and-tests-when-working-with-a-new-dataset
Baraa Khatib Salkini /Krishna Payyavula. «Your First Date with Data» — https://krishnapayyavula.github.io/blog/data_science/first-day-with-dataset/
Airbyte. «What is Data Profiling» — https://airbyte.com/data-engineering-resources/data-profiling
Eugene Yan. «Data Discovery Platforms and Their Open Source Solutions» — https://eugeneyan.com/writing/data-discovery-platforms/